
数据预处理

在进行任何分析之前,首先需要对原始数据进行清洗和预处理。这包括去除重复记录、修正错误信息、填补缺失值以及标准化格式等。这些步骤对于确保数据的准确性和一致性至关重要。例如,如果我们要分析一个包含数百万条用户行为日志的大型数据库,我们可能需要开发专门的算法来识别并删除异常值或者不相关的信息。
分布式计算

随着大数据集成技术的发展,分布式计算成为了一种高效处理超长分组任务的手段。在这种情况下,可以将大量工作负载分散到多个节点上,每个节点负责处理特定的子任务,并通过网络相互通信以实现协作。使用Hadoop或Spark这样的框架可以轻松管理这些分布式系统,从而加快了整个分析过程。
高级统计方法
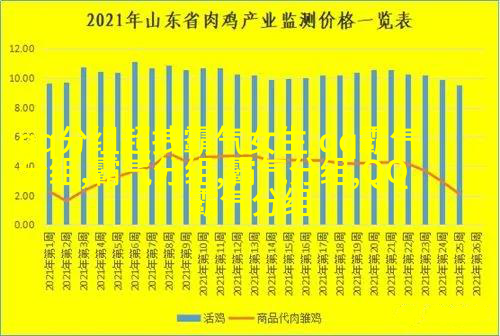
为了揭示隐藏在庞大数据中的模式和趋势,我们往往需要应用更为复杂和精细化的统计方法,如聚类分析、主成分分析(PCA)以及机器学习算法。此外,对于具有时间序列特性的数据,还可以利用时序模型如ARIMA或LSTM来捕捉动态变化,这些模型能够帮助我们理解历史趋势并预测未来的发展方向。
可视化工具与技术

可视化是理解复杂关系的一个强有力工具。在超长分组中,通过适当设计图表、地图或者其他类型的可视化对象,我们能够直观地展示出不同变量之间的联系以及它们如何影响整体结果。例如,在经济学研究中,可视化销售额与季节变化之间关系有助于决策者制定更加合理的人口普查计划,而在社会科学领域,则可以用热力图表示不同群体间交流频率,以此洞察社区结构。
伦理考量与隐私保护

面对如此庞大的个人隐私资料库,无论是用于商业还是学术目的,都必须严格遵守相关法律法规,同时考虑到个人隐私权利不受侵犯。这意味着在设计超长分组项目时,必须采取严格安全措施,比如采用加密技术,以及实施适当访问控制政策,以防止非授权人员获取敏感信息。此外,还需确保所有参与者都了解他们提供给我们的数据会被如何使用,并且获得必要同意。