
,count(1)直接读行数,复杂度是O(n),因为innodb真的要去数一遍。但好于具体的count(列名)
SELECT column, group_function(column) FROM table [WHERE condition] [GROUP BY group_by_expression] [ORDER BY column];
关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量。
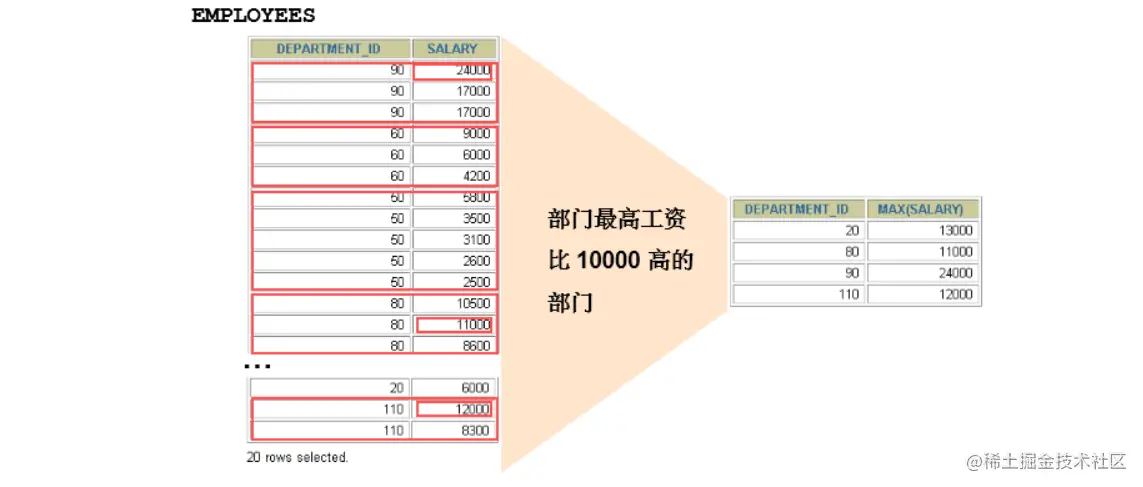

SELECT department_id, AVG(salary) FROM employees WHERE AVG(salary) 8000 GROUP BY department_id;

当过滤条件中没有聚合函数时,则此过滤条件声明在WHERE中或HAVING中都可以。但是,建议大家声明在WHERE中
区别1:WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。
这决定了,在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。这是因为,在查询语法结构中,WHERE 在 GROUP BY 之前,所以无法对分组结果进行筛选。HAVING 在 GROUP BY 之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是 WHERE 无法完成的。另外,WHERE排除的记录不再包括在分组中。
区别2:如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。
这一点,就决定了在关联查询中,WHERE 比 HAVING 更高效。因为 WHERE 可以先筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也比较高。HAVING 则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用的资源就比较多,执行效率也较低。小结如下:
WHERE 和 HAVING 也不是互相排斥的,我们可以在一个查询里面同时使用 WHERE 和 HAVING。包含分组统计函数的条件用 HAVING,普通条件用 WHERE。这样,我们就既利用了 WHERE 条件的高效快速,又发挥了 HAVING 可以使用包含分组统计函数的查询条件的优点。当数据量特别大的时候,运行效率会有很大的差别。
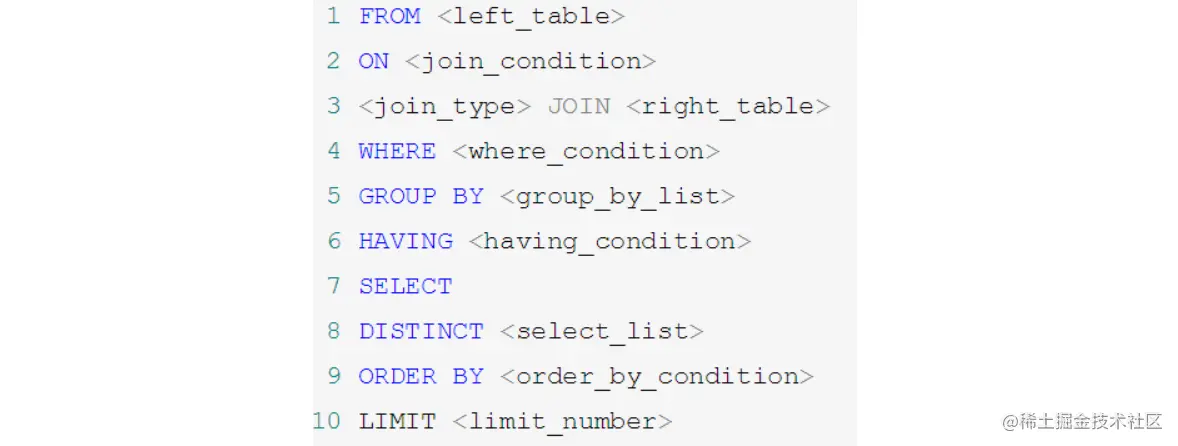
SELECT 是先执行 FROM 这一步的。在这个阶段,如果是多张表联查,还会经历下面的几个步骤:
添加外部行。如果我们使用的是左连接、右链接或者全连接,就会涉及到外部行,也就是在虚拟表 vt1-2 的基础上增加外部行,得到虚拟表 vt1-3。
当然如果我们操作的是两张以上的表,还会重复上面的步骤,直到所有表都被处理完为止。这个过程得到是我们的原始数据。
然后进入第三步和第四步,也就是GROUP 和 HAVING 阶段。在这个阶段中,实际上是在虚拟表 vt2 的基础上进行分组和分组过滤,得到中间的虚拟表vt3和vt4。
当我们完成了条件筛选部分之后,就可以筛选表中提取的字段,也就是进入到SELECT 和 DISTINCT 阶段。首先在 SELECT 阶段会提取想要的字段,然后在 DISTINCT 阶段过滤掉重复的行,分别得到中间的虚拟表vt5-1和
,得到最终的结果,对应的是虚拟表vt7。当然我们在写 SELECT 语句的时候,不一定存在所有的关键字,相应的阶段就会省略。
同时因为 SQL 是一门类似英语的结构化查询语言,所以我们在写 SELECT 语句的时候,还要注意相应的关键字顺序,**所谓底层运行的原理,就是我们刚才讲到的执行顺序。**更细致的内容参考后续的高级篇架构6. 课后练习
6.查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内
PHP中文网智能助手能迅速回答你的编程问题,提供实时的代码和解决方案,帮助你解决各种难题。不仅如此,它还能提供编程资源和学习指导,帮助你快速提升编程技能。无论你是初学者还是专业人士,AI智能助手都能成为你的可靠助手,助力你在编程领域取得更大的成就。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系
更多
更多
更多
[Bootstrap模板] bootstrap响应式宽屏图书教育网站模板-DREAMLIFE
[网站素材] 可爱的 happy birthday to you 字母矢量素材(AI+EPS+PNG)